
图1. 概念图。嵌段共聚物BCP在一定条件下可自组装形成特定纳米图案,通过定向自组装技术DSA结合深度学习预测,设计化学引导模板定向调控BCP自组装行为,实现可控纳米设计。
由于不同链段之间相互作用差异,嵌段共聚物(BCP)在体相中可自组装形成各种复杂有序的纳米尺度结构,为纳米制造、光刻、仿生等领域提供了各种候选基础结构。然而,在实际应用中,BCP体相自组装缺乏可设计性,研究人员通过嵌段共聚物定向自组装(DSA)来克服这一缺陷。DSA技术采用预先制造的粗糙化学/物理模板对BCP自组装行为进行定向调控,制造出特征尺寸为几到几十纳米的图案,其包含半导体领域所需的高分辨度点、线、折角等结构。与传统光刻技术相比,DSA能有效降低工艺成本,目前已经在FinFETs、储存器器件等制造领域得到应用。在模板设计方面,由于通过实验方法的设计效率有限,研究人员经常使用计算机模拟,如自洽场(SCFT)模拟,结合优化算法与机器学习技术,基于给定模板模拟DSA过程,并通过迭代不断优化模板。尽管如此,此类正向设计方法效率仍不高,尤其是对于需要数千次迭代才能达到预期结果的复杂目标图案来说。
针对上述挑战,复旦大学李剑锋课题组首次提出了一种仅使用机器学习来解决DSA引导模板反向设计的方法。相较于利用迭代与优化算法的正向设计方法,这种反向设计方法可以从目标自组装图案一步直接预测出可能的引导模板。本研究将复杂的DSA模板设计问题归结为多标签分类任务,使用自洽场(SCFT)模拟DSA过程,生成大量模板与图案样本构成数据集。从基本的两层卷积神经网络(CNN)到深度神经网络(具有8个残差块的32层CNN),训练了一系列神经网络(NN)模型;并提出了适用于自组装相形态相关问题、针对性很强的数据增强技术,以提高神经网络模型的性能。通过数据增强与模型结构优化,对测试集样本预测的全匹配准确率从基线模型的~59.8%显著提高到~97.1%。需要强调的是,该问题的随机预测准确率仅为1/225,可见该问题的挑战性以及本研究中模型优化方法的有效性。另外值得一提的是,最优模型不仅在模拟测试集上表现优异,对人工设计图案的模板预测任务同样表现出了出色的泛化能力,使用最优模型预测出的引导模板在模拟DSA过程后得到的自组装图案成功对人工设计图进行了重现。该研究表明,仅通过机器学习而无需任何正向模拟迭代,来解决DSA引导模板设计问题是可能的,从而大大提升了设计效率,尤其是对于较为复杂的目标图案。该研究以“Template Design for Complex Block Copolymer Patterns Using a Machine Learning Method”为题发表于《ACS Applied Materials & Interfaces》。本文的第一作者为复旦大学高分子科学系2021级博士研究生刘之菡,通讯作者为复旦大学高分子科学系李剑锋教授以及刘一新副教授。该研究得到国家自然科学基金等项目的支持。
本研究设计了一种5×5吸附点阵化学模板,模板基底对等臂AB两嵌段共聚物的两种嵌段都呈中性,基底上存在一些吸附点对A嵌段有吸附作用而对B嵌段呈中性,从而能够对BCP自组装行为进行定向调控。需要强调的是,吸附点的尺寸略大于半BCP固有周期,以实现粗糙模板引导BCP生成更高分辨率自组装图案的目标。随机生成了约9万个这样的点阵模板,并通过二维SCFT模拟DSA过程得到对应的BCP自组装图案(二值化后为40×40二值数组),构建为数据集。二维SCFT在x-y面上使用周期性边界条件,在z方向上对称。值得一提的是,由于SCFT模拟需要使用随机初场,会对模拟结果有一定影响,因此同一个引导模板用SCFT模拟DSA过程可能会得到几种不同的自组装图案,这种“多对一”关系也为模板预测带来挑战,本研究使用多通道输入策略(MCIS)来解决这一难题。
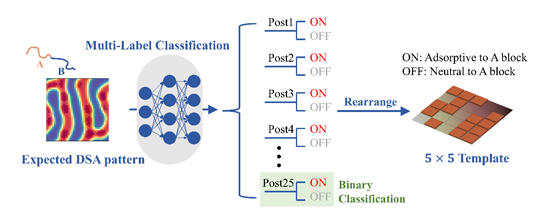
图2. 将DSA反向设计构建为多标签分类问题。本研究旨在设计一个5×5化学吸附点模板引导BCP生成目标图案,对应25个标签的二分类问题。

图3. DSA模拟得到的自组装图案经过一般的随机噪声增强(左),与界面噪声增强(右)。
本研究中使用的神经网络模型包括多种网络结构,包括全连接网络、卷积网络(CNN)、残差块(ResNet)和自省网络(SCN)。其中,CNN常用于图像识别,在二维数据特征提取方面特别有效。ResNet最初为了解决梯度消失问题而开发,目前已被广泛应用于各个领域。SCN模块是本文提出的一种跨层整合结构,背后的概念是利用神经网络的内部状态来提高其性能(有关更多详细信息,请参阅SI中的第二节)。基线模型拥有两个卷积层,记为CNN2,通过叠加卷积层深化网络,一共实验了4种CNN网络,包括CNN2,CNN8,CNN24,CNN32。通过叠加残差块,研究了残差结构对模型性能的影响,实验的网络结构包括CNN24-Res12,CNN32-Res8,CNN32-Res12,CNN32-Res16。在此基础上也研究了引入SCN模块对模型性能的影响。此外,还研究了单通道输入策略(SCIS)与多通道输入策略(MCIS)的性能对比。SCIS网络中,一个模板作为输出,一张SCFT模拟自组装图案作为输入;而在MCIS网络中,一个模板作为输入,对应五张SCFT模拟自组装图案作为输出。下文将模型结构统一记为X-CNNn-Resm-SCNY的形式,其中X可以是M(多通道输入)或S(单通道输入),n表示CNN层数,m表示残差块个数,Y可以是ON(有SCN模块)或OFF(无SCN模块)。具体网络结构参见SI中的表S1和S2。
需要说明的是,本研究使用全匹配准确率来评估模型性能,即准确率=5×5模板上25格全预测正确的样本数/总样本数。(如:随机预测下的全匹配准确率~1/225)
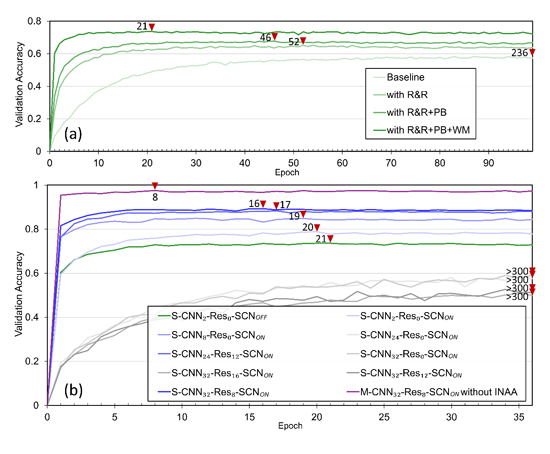
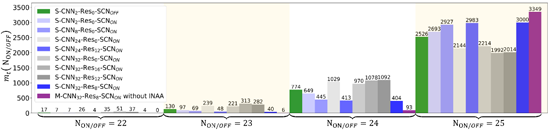
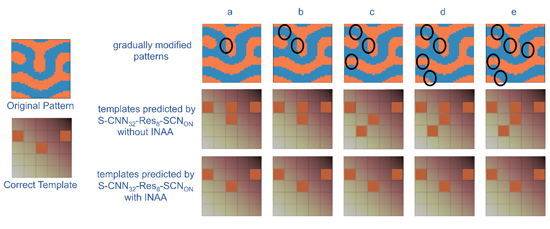
图6. INAA提高NN泛化能力。左侧显示数据集中的一个样本,包括输入图案及正确模板。右侧显示了当该输入图案逐渐改变时(改变处由相界面上的黑圈标出),引入和不引入INAA下训练模型S-CNN32-Res8-SCNON预测出的对应模板。引入INAA(第三行)训练的模型始终能预测出正确的模板,而不引入INAA(第二行)训练的模型在输入图案变化时会预测出不同的模板。
尽管最佳模型在基于SCFT模拟生成的DSA图案模板预测方面实现了高准确度(~97.1%),但在实际的反向设计中,目标DSA图案通常由工程师而不是SCFT设计。这些人工设计(HD)图案的相界面通常与SCFT模拟得到的DSA图案相界面不同,这可能会对仅基于SCFT数据训练的NN模型提出挑战。因此,本研究使用HD图案来评估NN模型在光刻中的反向设计性能。与使用SCFT模拟图案时提供“真实”模板来评估模型不同,此任务中没有“真实”的模板。因此,本研究以模型预测的模板进行SCFT模拟,以确定由预测的模板引导的嵌段共聚物微相分离是否确实会产生所需的图案。在不同的初始场下模拟得到数个DSA图案,如果这些图案中的一个与期望的图案相似,则认为该HD图案的反向设计任务是成功的。
结果表明,引入INAA训练的最佳模型M-CNN32-RES8-SCNON(Bestinaa模型)在这项任务中表现最好,成功地再现了大约一半的HD图案,而不引入INAA训练的最佳模型只能再现少数HD图案。另外,基线模型在这项任务中性能较差,会预测出与Bestinaa模型明显不同的模板(图7)。
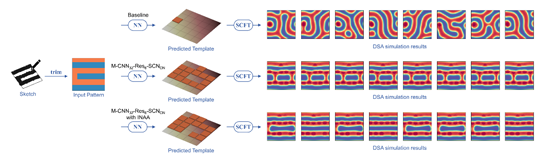
图7. 人工设计图案(HD)反向设计示例。手工绘制设计图并将其转换为40×40二值数组,然后将其输入训练后的NN。NN预测出一个可能的5×5模板。然后通过SCFT在不同的初始条件下进行DSA模拟。引入INAA训练的最佳模型(第三行)成功地引导BCP自组装形成类似于设计图的DSA图案,而不引入INAA训练的最佳模型(第二行)没有成功还原设计图。基线模型(第一行)表现最差,模拟得到的图案与所需图案完全不同。
原文链接:https://doi.org/10.1021/acsami.3c05018
- 南邮赵强教授、李杨教授团队 Matter: 可拉伸OECT助力高保真电生理监测与深度学习辅助睡眠分析 2025-03-25
- 太原理工张虎林教授 JMCA:深度学习辅助的透气热电水凝胶阵列用于自供电心理监测 2025-03-20
- 郑州大学申长雨院士和刘春太教授团队 AFM:解耦的温度-压力传感器基于深度学习算法辅助的人机交互应用 2024-08-23
- 南开大学史伟超教授课题组 JACS:建立高密度阳离子型嵌段共聚物合成方法 - 揭示不对称自组装机理 2026-06-09
- 天津大学宋东坡教授/复旦大学李卫华教授 Angew:非对称瓶刷嵌段共聚物相图 - 发现稳定六方穿孔层状结构(HPL) 2026-04-22
- 复旦大学彭娟团队 Macromolecules: 分子工程实现共轭嵌段共聚物结晶取向的高效调控 2026-04-07
- 复旦大学朱亮亮研究员课题组实现嵌端共聚物磁铁控制的定向自组装 2019-01-25
