有图无真相
在打击学术造假的征途上,学术规范机构又下一城。
来自美国纽约雪城大学(Syracuse University)的机器学习研究员丹尼尔·阿库纳(Daniel Acuna)等在2018年开发出一套算法,能利用人工智能(AI)识别学术论文中的图像造假,对论文图片进行查重。
他们分析了生命科学领域来自4324本期刊的76万篇开放获取(Open Access)论文,并从中提出有效的263万张图片。其中,约有9%的图像存在高度重复。该团队又在其中选取了约4000张可疑图片进行人工核查。经测算,在所有论文中,约1.5%存在学术不端的嫌疑,0.6%确认存在图像方面的论文造假。
在学术造假上,图片是藏污纳垢的死角。《科学》(Science)杂志和《撤稿观察》(Retraction Watch)2018年发布报告称,在过去10年里,学术期刊撤回的论文数量增加了10倍。这些论文中,约有1.7%是因为篡改了论文图像被撤回。
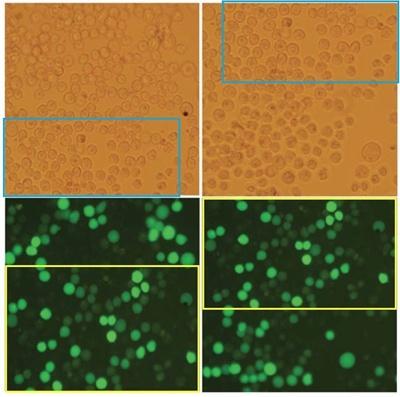
图片造假的案例
美国宾夕法尼亚大学生物工程副教授阿荣·拉杰(Arjun Raj)早在2012年就指出,一篇生命科学领域的研究论文背后的科学成本约为30万-50万美元。2012年全年,美国研究人员共发表该领域论文15.2万篇。如果其中1.7%因图片造假需要被撤回,则仅在2012年,因此造成的损失就接近10亿美元。
根据出版机构的统计,全球科学产量每9年就会翻番。
过去,图片审核工作往往要靠人力完成,几乎没有自动化的流程。《自然》(Nature)杂志会对收到的稿件随机抽样进行检查,并要求作者提供未编辑的图像作参考;生命科学领域的重要刊物《细胞生物学杂志》(Journal of Cell Biology)和《欧洲分子生物学组织杂志》(The EMBO Journal)会对图片进行手动查重。
2018年6月,来自斯坦福大学的微生物学家分析了2009-2016年发表在《分子与细胞生物学》(Molecular and Cellular Biology)上的960篇论文,发现其中59篇含有“不适当的”重复图像,约有2%值得再去进行图像证伪。他们将情况反映给出版机构后,42篇论文更正了图片,5篇被撤稿。
图片查重费时费力,以至于多数刊物都没有这项流程。《欧洲分子生物学组织杂志》主编表示,人工筛选非常耗时,早就应该有一个常规的、自动化的工具简化这一过程。
美国诚信研究办公室(the United States Office of Research Integrity, 简称ORI)的数据显示,图片造假的情况一直在恶化,标志性的两个时间是1990年和1996年,Photoshop的Mac版和PC版在这两年发布。
但即使是ORI,每年也仅报告了10例图片造假的行为。因为成本过高,他们不会主动审查学术不端,仅在有举报的情况下进行。
自诞生起,学术论文就承担着描述科研成果、进行学术交流的重任。它还被用来衡量学者的学术水平,是评定职称、获取科研经费等环节中考察的重要的内容。因此,判断一篇学术论文是否由抄袭、造假得来至关重要。
在计算机技术不够发达、数据库尚未开放共享的时代,识别学术不端不得不依靠评审编辑慧眼如炬。在中国,论文文字查重体系一直到2005年前后才建立。后来,人们又不断优化这个系统,从能识别“复制粘贴型”抄袭,到能识别改变用词和句法的抄袭,但图片重复一直是论文查重的死角。
道高一尺,魔高一丈,心怀不轨的研究人员已经学会了应付能识别文字抄袭的系统。在生命科学等依赖图像实物的研究领域,图片造假的难度和成本会更高。
2014年轰动学术圈的小保方晴子学术造假丑闻中,她的团队被发现使用了小保方晴子博士学位论文中的图片,用来证明新的发现。更多时候,造假来得更隐秘,研究人员用旋转、裁剪、调整大小和对比度的方式调整图片。它们常常难以被察觉,直到前赴后继的科研人员发现研究成果无法复现。此时,大量的人力和资金成本都被浪费了。
如何解决这个问题,仍然是摆在我们面前的一座大山。即使是丹尼尔·阿库纳等人开发出的算法,也面临很大的困难。在每一个领域,我们需要专业人士进行足够数量的前期人工标注。
这套算法的运算速度也有限,目前只能考察作者自己发表的诸多论文中是否存在重复,尚无法应对以亿为单位的出版文献库。出版巨头爱思唯尔(Elsevier)诚信部门主管也表示,出版商需要创建一个共享的数据库,以便进行相关检索,查实论文图片重复使用的情况。
我们似乎无法阻止“魔”的存在,只能努力让“道”高得快一点。
- 草菅人命的学术造假 2016-07-27
- 南开校长倡议建第三方处理机制遏止学术造假 2011-11-29
- 评论:学术造假与科研经费造假是一根藤上俩烂瓜 2011-09-05
